Data Engineering
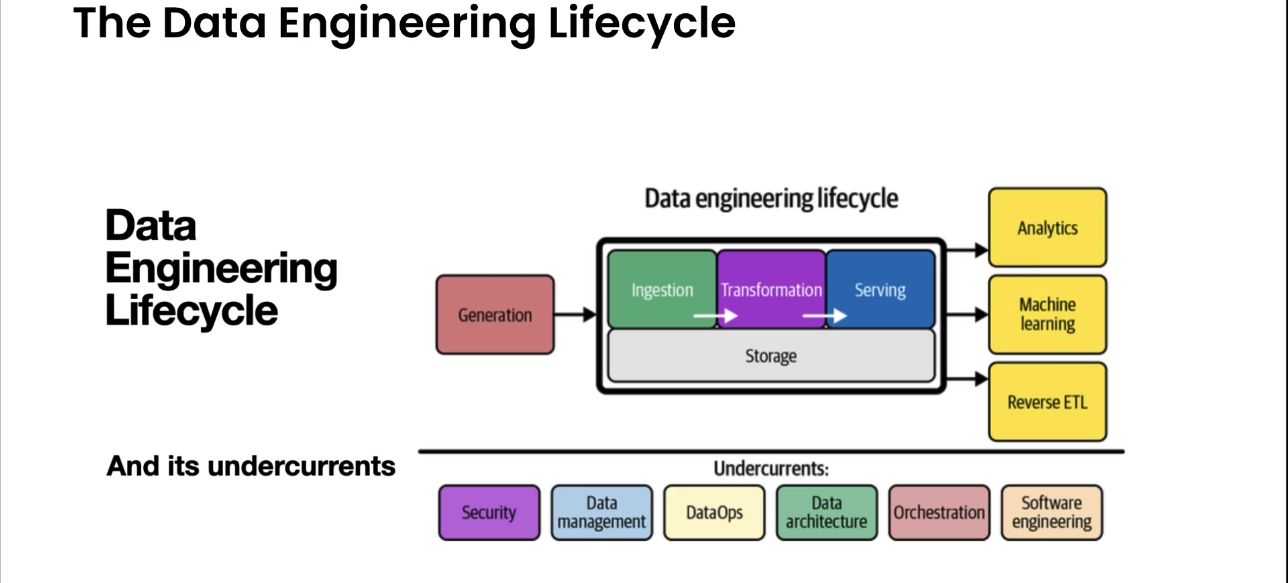
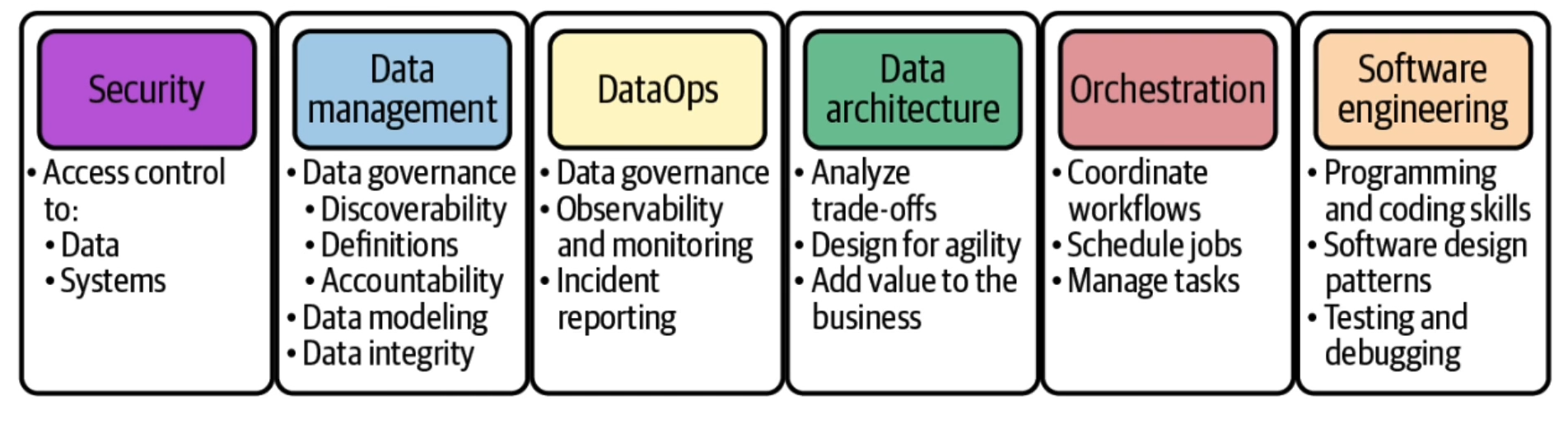
Data engineering is a development implementation and maintenance of systems and processes that take in raw data and produce high quality consistent information. That supports Downstream use cases such as analysis and machine learning data engineering is the intersection of security data management, data Ops, data architecture, orchestration and software engineering.
- Designs, builds and maintains data infrastructure.
- Manages the data engineering lifecycle
- Ensures data is available for use in other data use cases
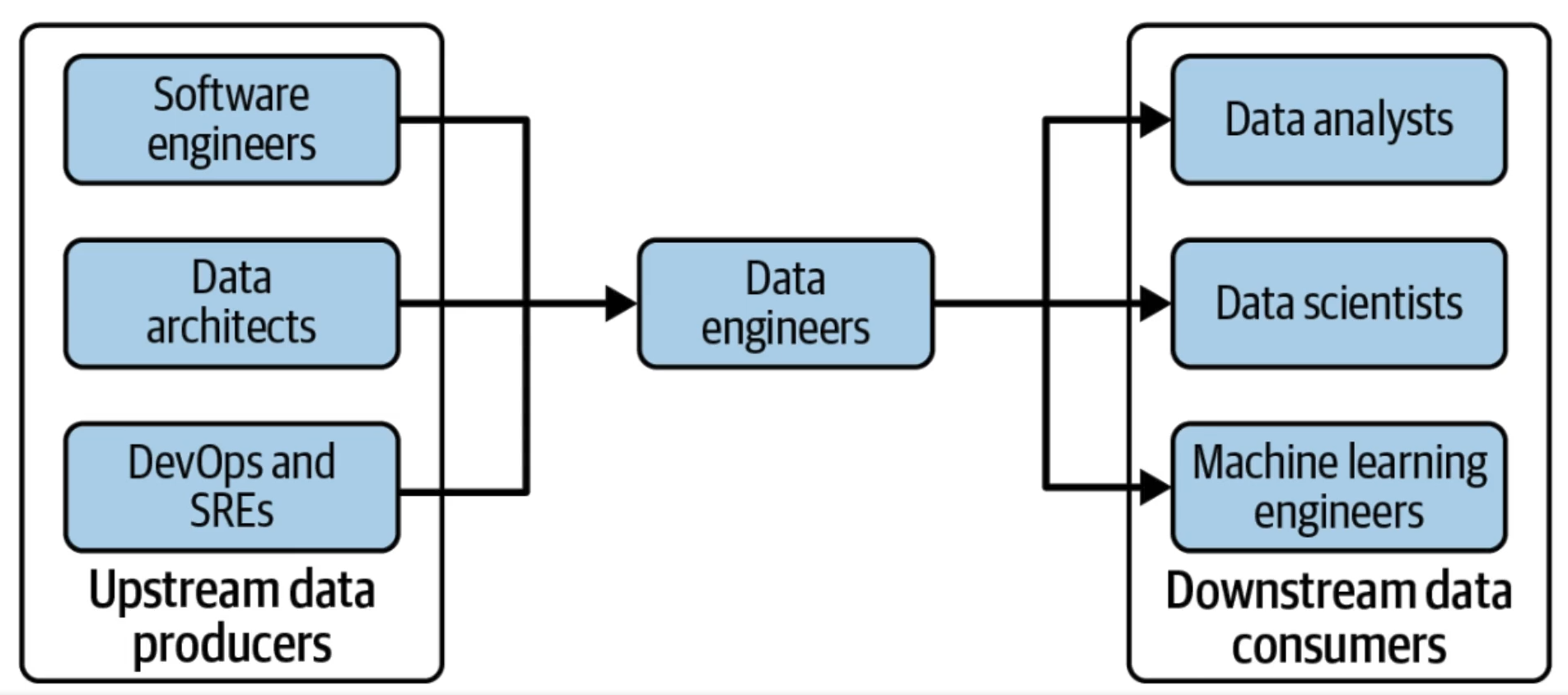
Upstream & Downstream data consumers
Stages/Lifecycle
Tip
Never shoot for the best architecture, but rather the least worst architecture. Good data arch is a living, breathing thing. It is never finished.









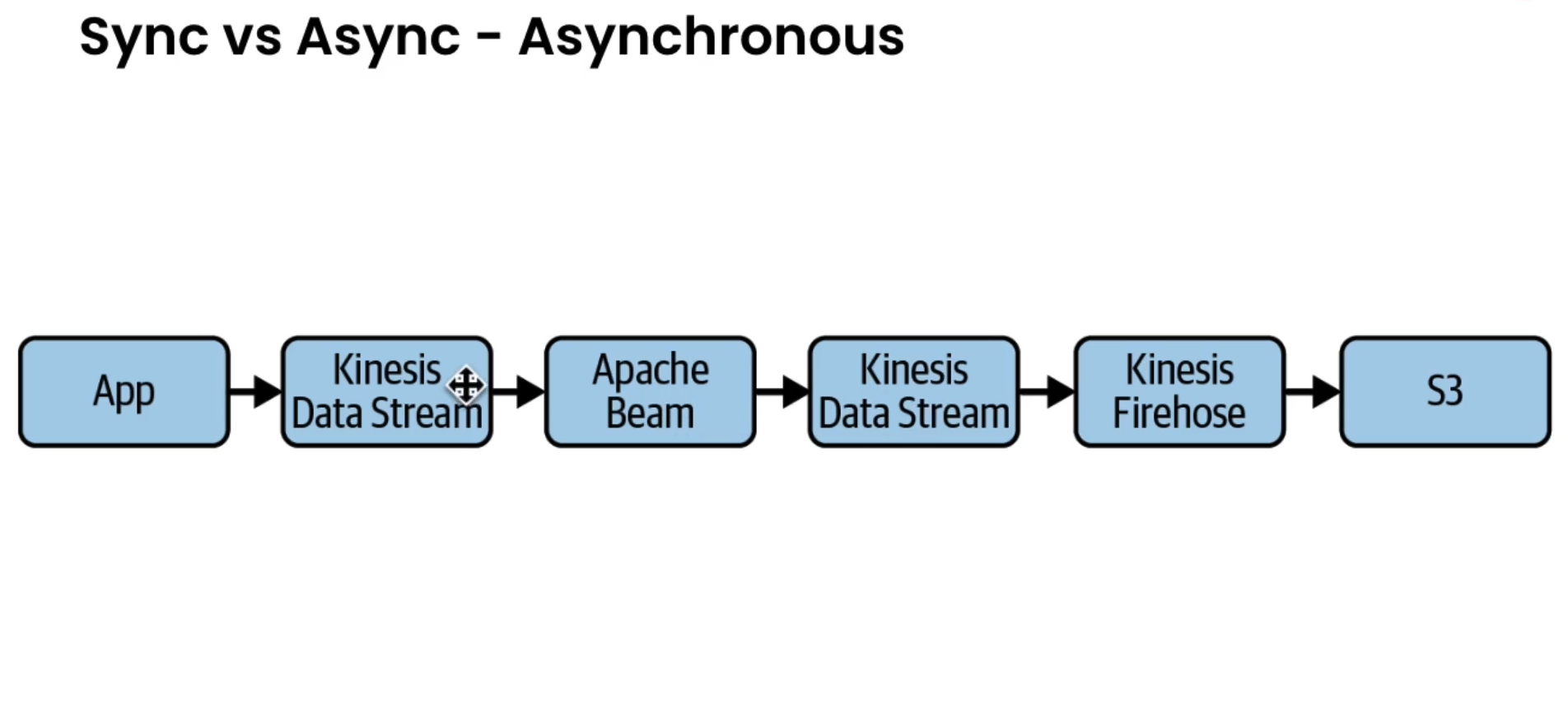











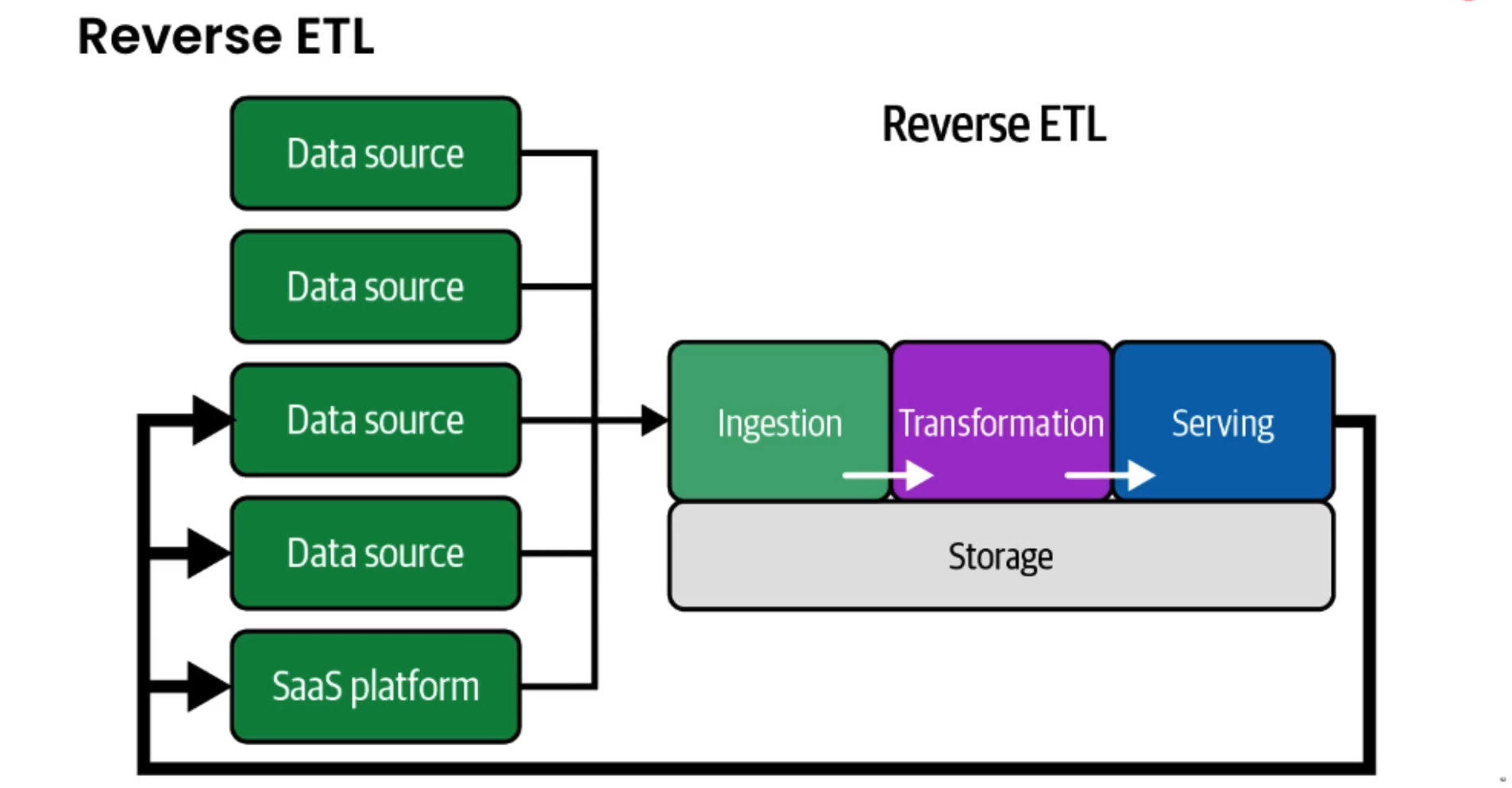
Reverse ETL
- Taking the data from the warehouse and feeding it back to our systems or applications or third-party APIs like Google Ads
- Think of it as a pipeline that connects our data warehouse to the rest of our organization
- This allows us to easily provide the rich customer data that lives in our warehouse broadly across our business for teams to actually use.
DataOps
- Just like DevOps
- DevOps principles:
- Build
- Test
- Release
- Monitor
- Plan
- DevOps principles:
- Maps the best practices of Agile Methodologies, DevOps and Statistical Process Control (SPC) [the use of statistical techniques to control a process or production method]
- Rapid Innovation
- High data quality and very low error rates
- Tools like Airflow help in this direction
- As Werner Vogels, CTO of Amazon Web Services, is famous for saying, “Everything breaks all the time.” Data engineers must be prepared for a disaster and ready to respond as swiftly and efficiently as possible.
Orchestration
- Orchestration is the process of coordinating many jobs to run as quickly and efficiently as possible on a scheduled cadence.
- Like Airflow
- Argo is an orchestration engine built around Kubernetes primitives
- Orchestration is strictly a batch concept. Streaming DAG is difficult to build and maintain.
Data Architecture
- Data architecture is the design of systems to support the evolving data needs of an enterprise, achieved by flexible and reversible decisions reached through a careful evaluation of trade-offs.
- "Never shoot for the best architecture, but rather the least worst architecture."
Principles of Good Data Architecture
- Choose Common Components Wisely
- Plan for Failure
- Architect for Scalability
- Build Loosely Coupled Systems
- Make reversible decisions
- be prepared to upgrade or adopt to better practices as the landscape evolves
- Just like Bezos said:
- "If you walk through and don’t like what you see on the other side, you can’t get back to before. We can call these Type 1 decisions. But most decisions aren’t like that—they are changeable, reversible—they’re two-way doors." Aim for two-way doors whenever possible.
- Aim for multi-tier architecures
- seperate data from the application; and
- application from the presentation
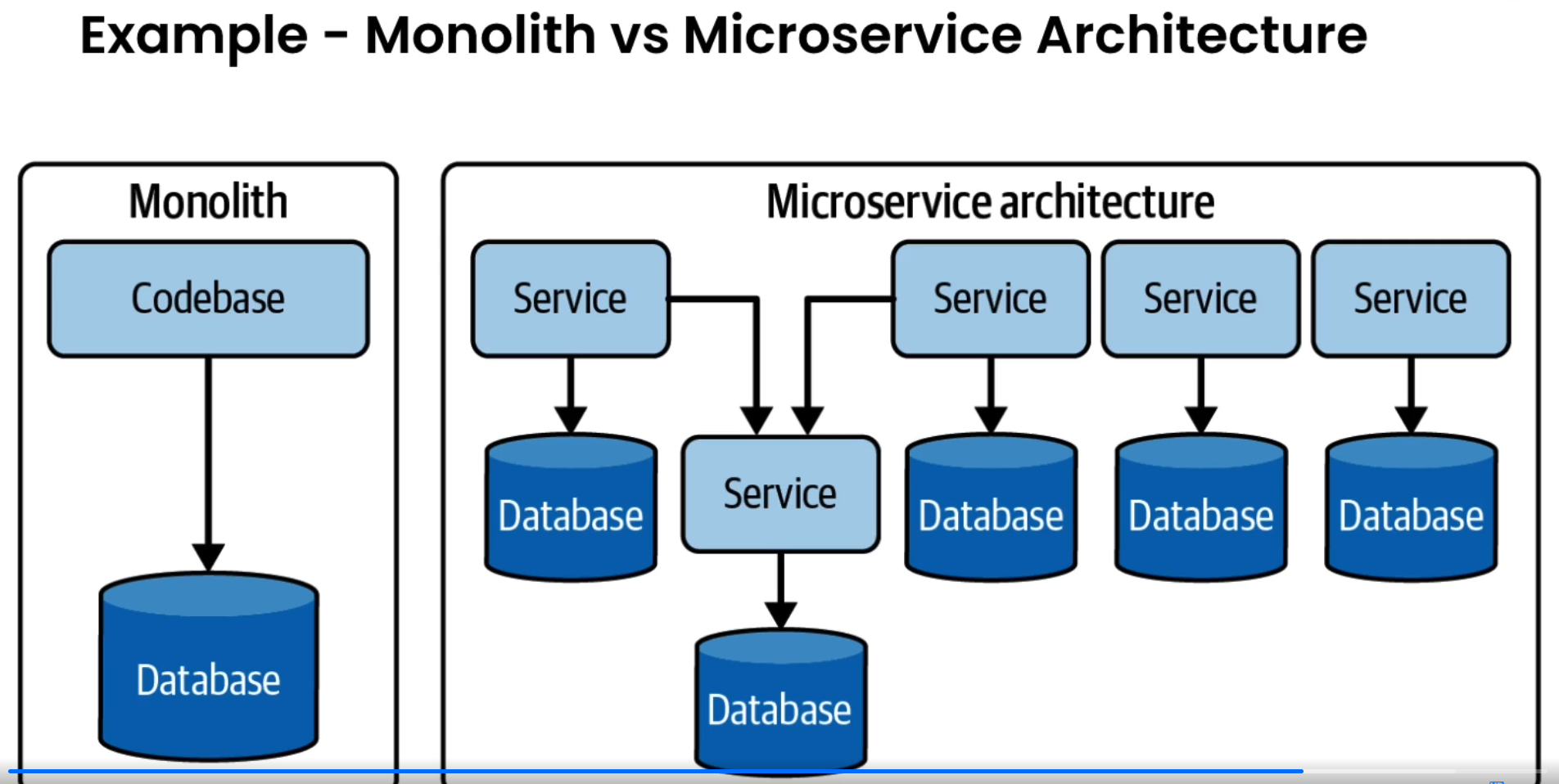
- Monolithic applications are a single codebase. All in one.
Brownfield vs Greenfield Projects
Brownfield
- Brownfield projects often involve refactoring and reorganizing an existing architecture and are constrained by the choices of the present and past.
- Brownfield projects require a thorough understanding of the legacy architecture and the interplay of various old and new technologies.
Greenfield
- Start afresh.
- Unconstrained by history or legacy of prior architecture.
Types of Data Architectures
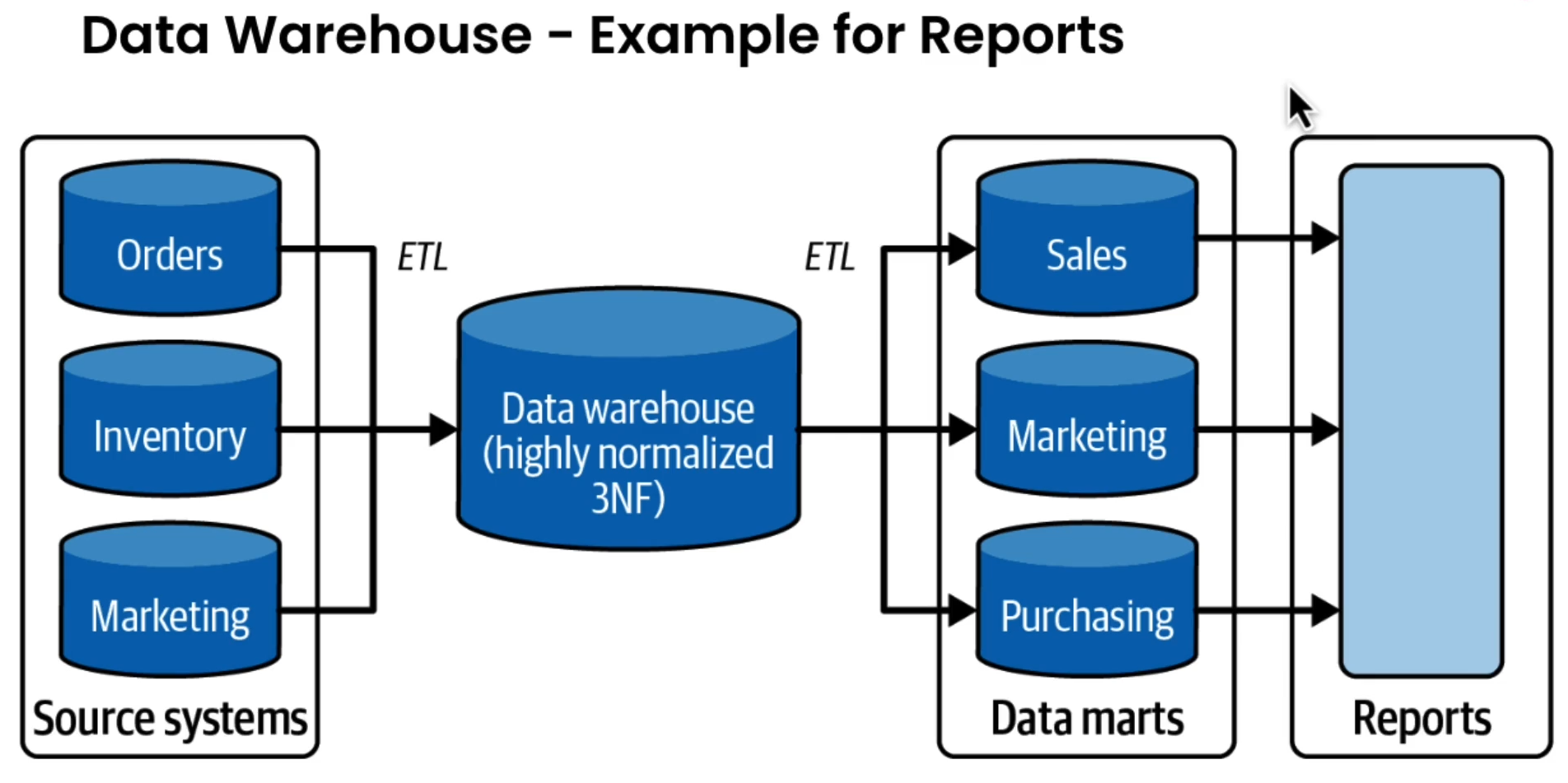
Data Warehouse
- A data warehouse is a central data hub used for reporting and analysis.
- Data in a data warehouse is typically highly formatted and structured for analytics use cases.
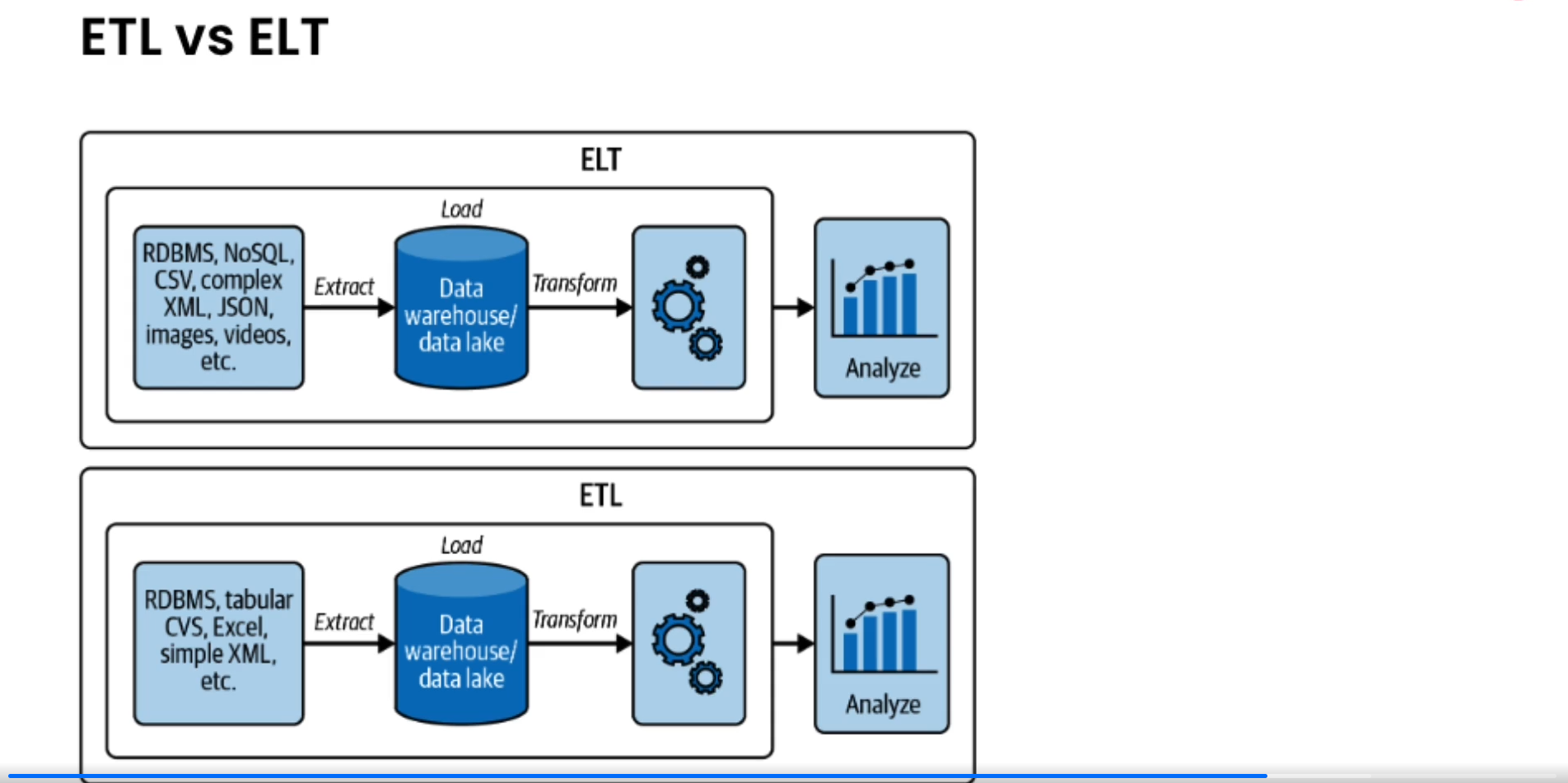
- ELT
- With the ELT data warehouse architecture, data gets moved more or less directly from production systems into a staging area in the data warehouse.
- Staging in this setting indicates that the data is in a raw form. Rather than using an external system, transformations are handled directly in the data warehouse.
- The intention is to take advantage of the massive computational power of cloud data warehouses and data processing tools. Data is processed in batches, and transformed output is written into tables and views for analytics.
- A second version of ELT was popularized during big data growth in the Hadoop ecosystem. This is transform-on-read ELT.
Data Marts
- A data mart is a more refined subset of a warehouse designed to serve analytics and reporting, focused on a single suborganization, department, or line of business; every department has its own data mart, specific to its needs.
- Data marts exist for two reasons.
- First, a data mart makes data more easily accessible to analysts and report developers.
- Second, data marts provide an additional stage of transformation beyond that provided by the initial ETL or ELT pipelines. This can significantly improve performance if reports or analytics queries require complex joins and aggregations of data, especially when the raw data is large.
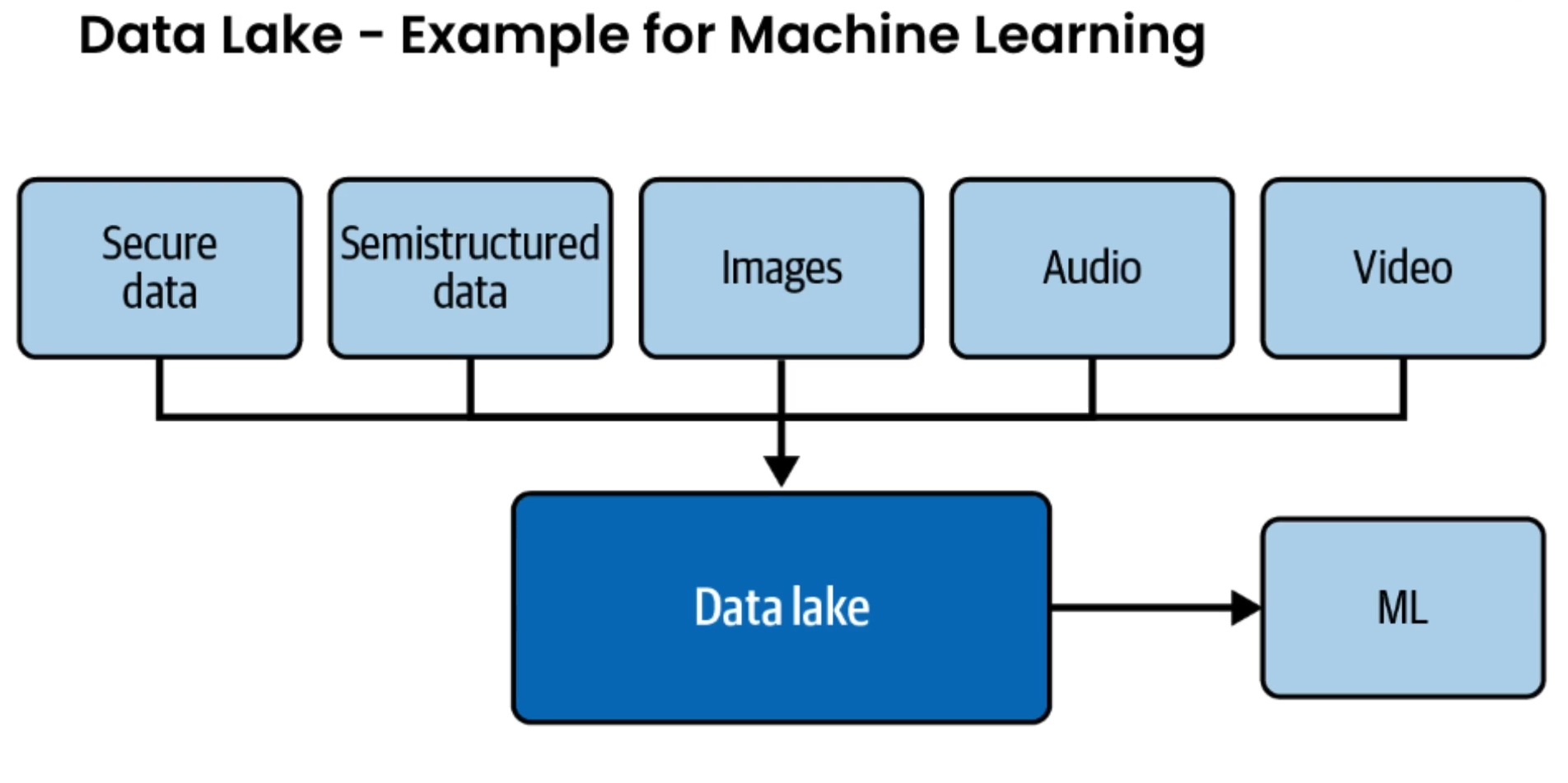
Data Lake
- Simple: dump all of your data—structured and unstructured
- But became a problem like processing, no fixed schema
- Now, the convergence between data lake and data warehouse is there.
- Shortcomings
- Despite the promise and hype, data lake 1.0 had serious shortcomings. The data lake became a dumping ground; terms such as data swamp, dark data, and WORN were coined as once-promising data projects failed. Data grew to unmanageable sizes, with little in the way of schema management, data cataloging, and discovery tools.
- Processing data was also challenging. Relatively banal data transformations such as joins were a huge headache to code as MapReduce jobs.
- Simple data manipulation language (DML) operations common in SQL—deleting or updating rows—were painful to implement, generally achieved by creating entirely new tables.
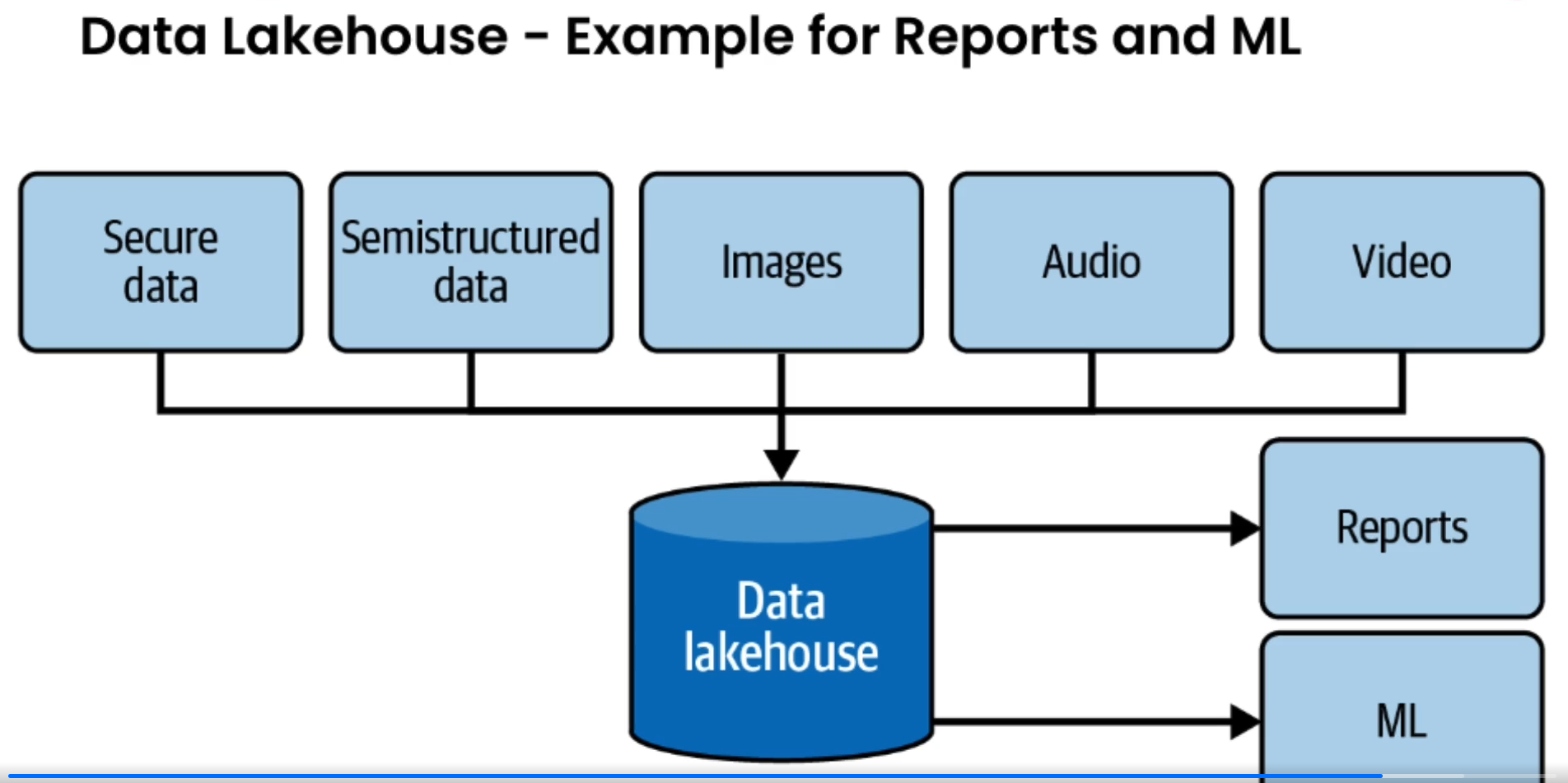
Data Lakehouse
- Introduced by Databricks
- The lakehouse incorporates the controls, data management, and data structures found in a data warehouse while still housing data in object storage and supporting a variety of query and transformation engines.
- In particular, the data lakehouse supports atomicity, consistency, isolation, and durability (ACID) transactions, a big departure from the original data lake, where you simply pour in data and never update or delete it.
- The technical architecture of cloud data warehouses has evolved to be very similar to a data lake architecture. Cloud data warehouses separate compute from storage, support petabyte-scale queries, store a variety of unstructured data and semistructured objects, and integrate with advanced processing technologies such as Spark or Beam.
Important
Given the rapid pace of tooling and best-practice changes, we suggest evaluating tools every two years.
Conception of Data Lake
Sources of Data
- APIs
- They are the standard way of exchanging data between the systems
- File & Unstructured Data
- csv, parquet, txt, json etc
- Application Database (OLTP systems)
- Typically an app database is an online transaction processing system: a db that reads and writes individual data records at a high rate.
- OLTP dbs are often referred to as transactional db but this doesn't necessarily means that the system in question supports ATOMICITY.
- OLTP db supports low latency and high concurrency.
- Less suited for analytics (analyzing vast amount of data)
- ACID
- ATOMICITY: yes or no
- CONSISTENCY: any db read will return the last written version of the retrieved item
- ISOLATION: if two updates are in flight concurrently for the same thing, the end database state will be consistent with the sequential execution of these updates in the order they were submitted
- DURABILITY: once commited, never lost; even in the case of power loss
- OAPS
- Online Analytical Processing System built to run large analytical queries and is typically inefficient at handling lookups of individual records.
- CDC
- Change Data Capture is a method for extracting each change event (insert, update, delete) that occurs in a db
- frequently leveraged to replicate db in real-time or to trigger a downstream task
- Logs
- Streams
- RDBMS
- Relational Database Management Systems
- Data is stored in a table of relations(rows) and each relation contains multiple fields (columns).
- Each relation in the table has a fixed schema
- Rows are typically stored as a contiguous seq of bytes on a disk
- Tables are typically indexed by a primary key, a unique field for each row in the table
- They may also have a foreign key -- fields with values connected with the values of primary keys in other tables, facilitating joins
- Normalized Schema can be designed for ensuring that data in records is not duplicated in multiple places, thus avoiding the need to update states in multiple locations at once and preventing inconsistencies
- RDBMS are typically ACID compliant
- NoSQL
- Not only SQL
- abandon the relational paradigm
- Various flavors:
- Key-value stores
- Document stores
- Document -- nested object
- think of each document as JSON object
- stored in collections
- a collection is roughly equivalent to a table in relational db
- Wide-column
- optimized for storing massive amounts of data with high transaction rates and extremely low latency
- only have a single index
- Graph Databases
- queries based on the connectivity between the elements
- nodes and edges
- REST
- Representational State Transfer
- Interactions are stateless
- each REST call is independent
- GraphQL
- create at Facebook
- retrieve multiple data models in a single request
- built around JSON and returns data in a shape resembling the JSON query
- gRPC
- from Google
- efficient bidirectional exchange of data over HTTP/2
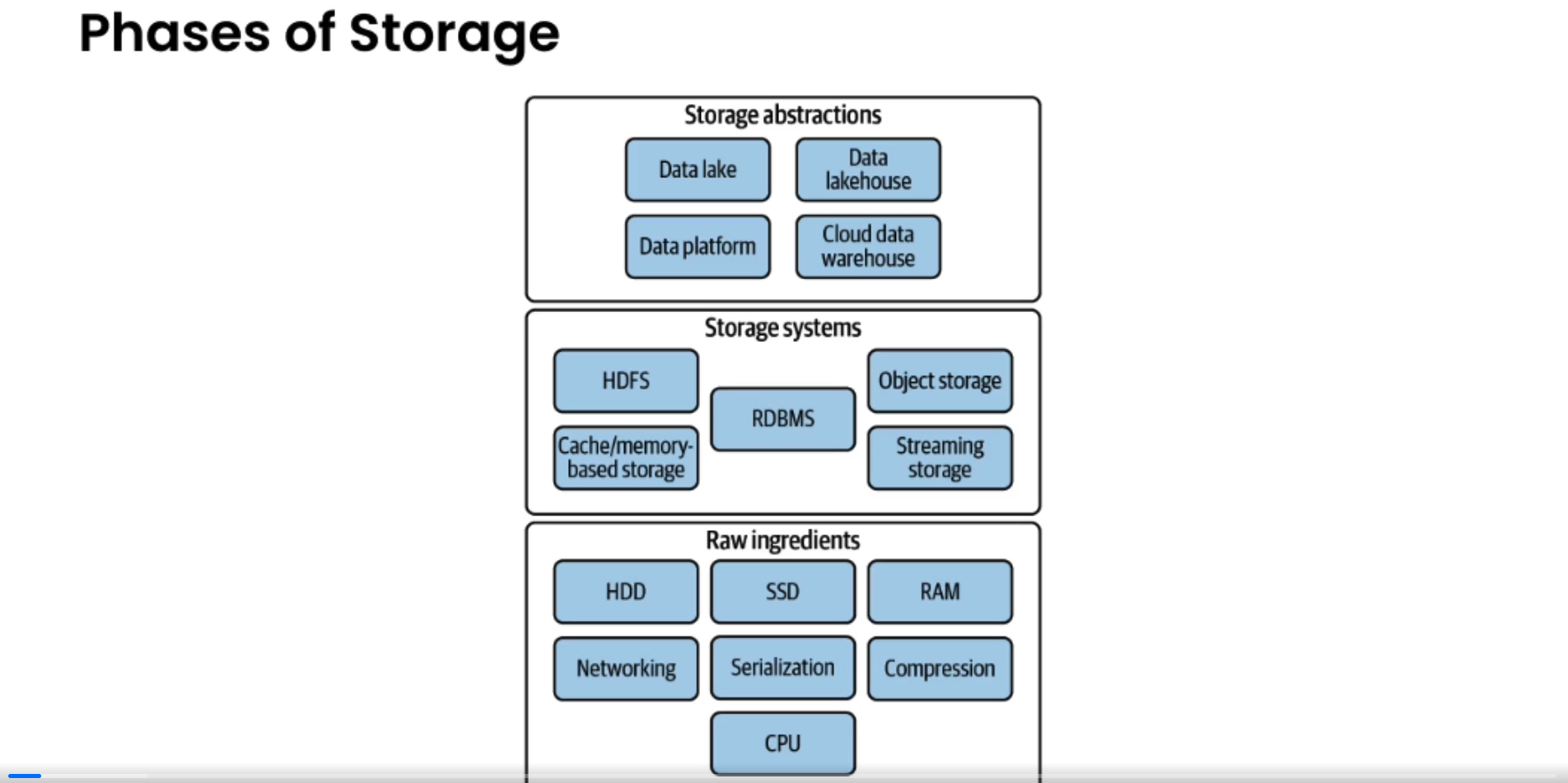
Storage
- Due to increased data complexities, it becomes necessary to distribute the data across multiple servers for:
- Redundancy
- Scalability
- FT
- Apache Spark, object storage and cloud data warehouses rely on distributed storage architectures.
Block Storage - Raw storage provided by SSDs and magnetic disks - A block is the smallest addressable unit of data supported by a disk - Default option for OS boot disks on cloud VMs
RAID - Stands for Redundant Array of Independent Disks - Simultaneously controls multiple disks to improve data durability, enhance performance and combine capacity from multiple drives
Object Storage - Contains objects of all shapes and sizes - csv, images, json, audio, video etc - Cloud ex: Amazon S3, Azure Blob Storage, GCS
Cache and Memory-Based Storage Systems - RAM offers excellent latency and transfer speeds but power-failure always leads to data loss - Ultra-fast cache systems include: - Redis - key-value store with support for complex types (set, lists) - Memcached
Hadoop Distributed File System - Based on Google File System (GFS) - Similar to object storage but with a key difference: It combines compute and storage on the same node - Hadoop breaks large files into blocks, less than few hundred MBs in size - Data is also replicated across nodes (prob of data loss is very low) - Hadoop is not simply a storage system. It combines compute resources with storage nodes to allow in-place data processing (originally achieved using the MapReduce programming model) - Core element of Amazon EMR, Apache Spark Processing
Eventual vs Strong Consistency
- As data is spread across multiple servers, there will be latency.
- Two common consistency patterns in distributed systems are:
- eventual (BASE)
- strong (ACID)
BASE - Basically Available, Soft-state, Eventual Consistency - Basically Available means consistency is not guranteed but the db reads and writes will be replicated on the best-effort basis and will get consistently available most of the time - Soft-state means the state of the transaction is fuzzy and it's uncertain whether the transaction is committed or uncommitted - Eventual Consistency means at some point, reading data will return consistent values
- It really depends on the use-case whether to stick by ACID or BASE. For ex, DynamoDB supports eventually consistent reads and strongly consistent reads. Strongly consistent reads are slower and consume more resources, so it is best to use them sparingly, but they are available when consistency is required.
Indexes, Partitioning and Clustering
- Indexes
- provide a map of the table for particular fields and allow extremely fast lookup of individual records
- Without indexes, a database would need to scan an entire table to find the records satisfying a WHERE condition.
- In RDBMS, indexes are used for primary table keys and foreign keys but can be applied to other columns also.
Info
- Columnar DBs pack the similar values next to each other, yielding high-compression ratios with minimal compression overhead.
- Allows db to scan only the columns required for a particular query, increasing the speed.
- Partition & Clustering
- While columnar databases allow for fast scan speeds, it’s still helpful to reduce the amount of data scanned as much as possible.
- In addition to scanning only data in columns relevant to a query, we can partition a table into multiple subtables by splitting it on a field.
- A clustering scheme applied within a columnar database sorts data by one or a few fields, colocating similar values. Improves performance for filtering, sorting and joining these values.
- Best example: Snowflake micro-partitioning
Snowflake Micro-partitioning
- Micro partitions are set of rows b/w 50-500 MB in uncompressed size
- Uses an algo to cluster together similar rows
- Snowflake specifically looks for values that are repeated in a field across many rows. This allows aggressive pruning of queries based on predicates. For example, a WHERE clause might stipulate the following:
WHERE created_date='2022-01-02'
- In such a query, Snowflake excludes any micro-partitions that don’t include this date, effectively pruning this data
- Efficient pruning is facilitated by Snowflake’s metadata database, which stores a description of each micro-partition, including the number of rows and value ranges for fields.
Info
Schema is the expected form of data. Instructions that tell us how to read the data. Of two types:
-
Schema on write: table has an integrated schema. Must conform to that.
-
Schema on read: dynamically created when the data is written. More flexible.
Info
Seperation of compute and storage provides:
-
scalability
-
durability
-
availability
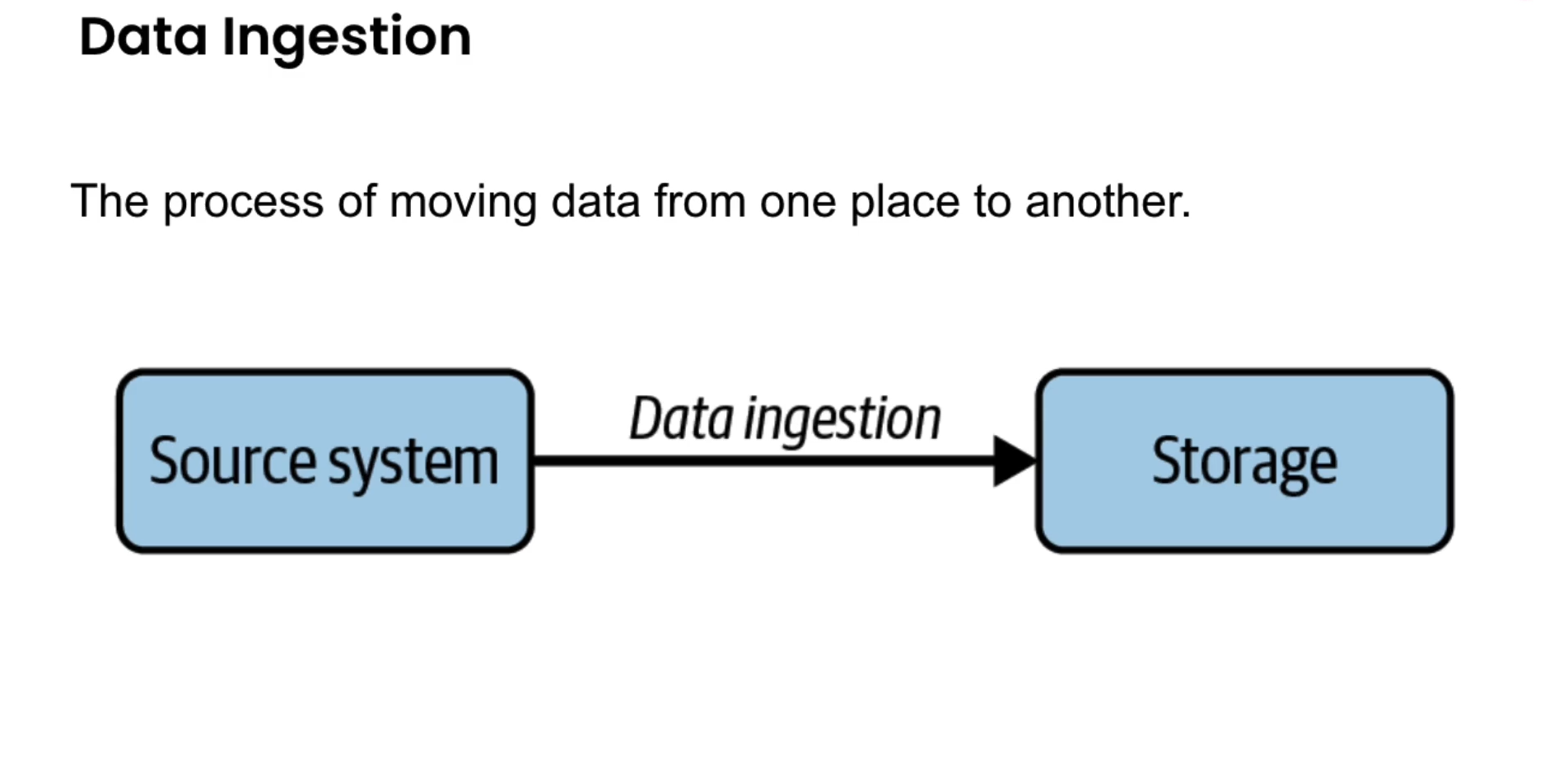
Ingestion
Types of Data
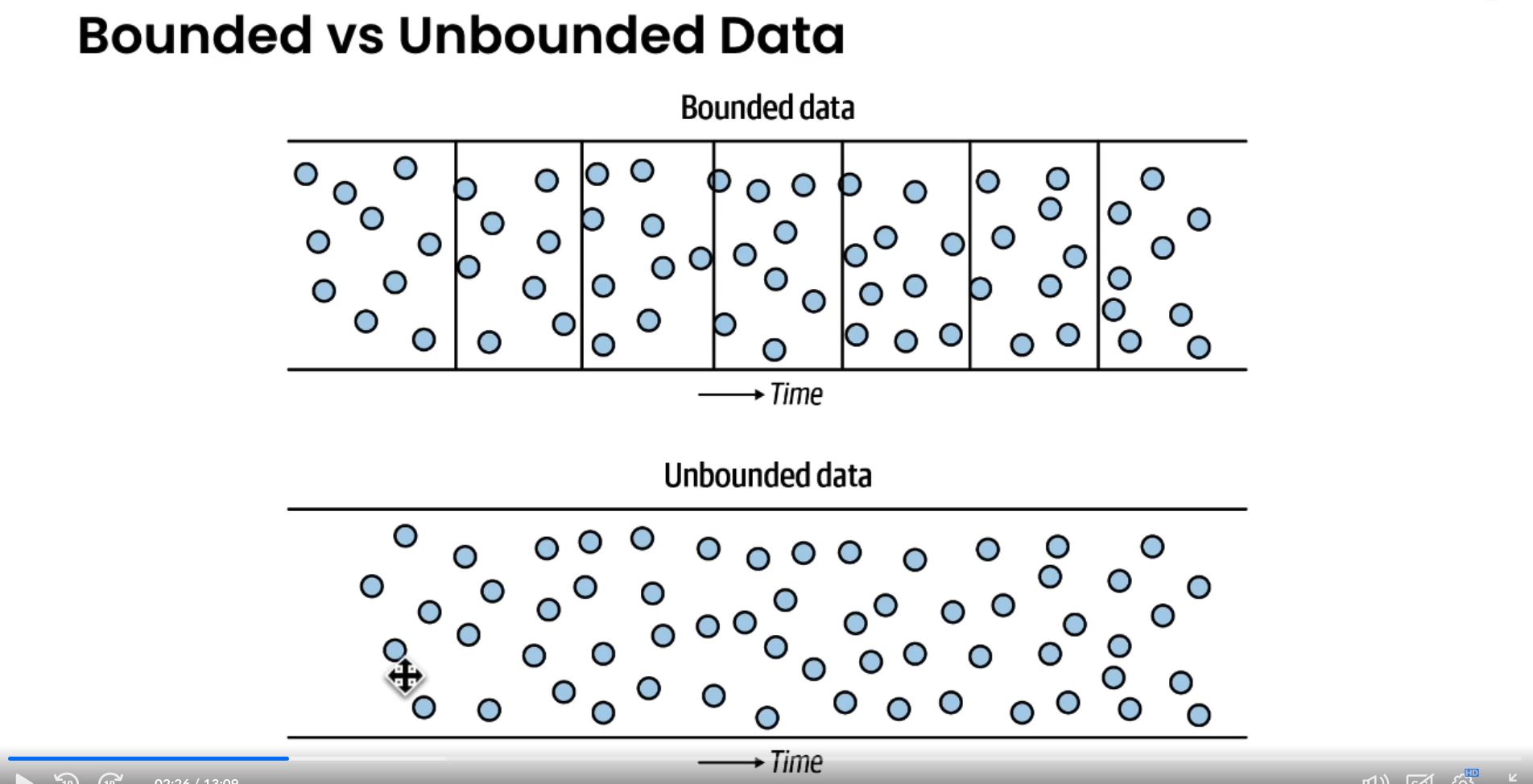
Bounded vs Unbounded Data
- Unbounded data is data as it exists in reality, as events happen, either sporadically or continuously, ongoing and flowing.
- Bounded data is a convenient way of bucketing data across some sort of boundary or time.
Info
- No ingestion system is genuinely real-time. There will always be some kind of latency.
- Better to say like near real-time.
Types of Ingestion
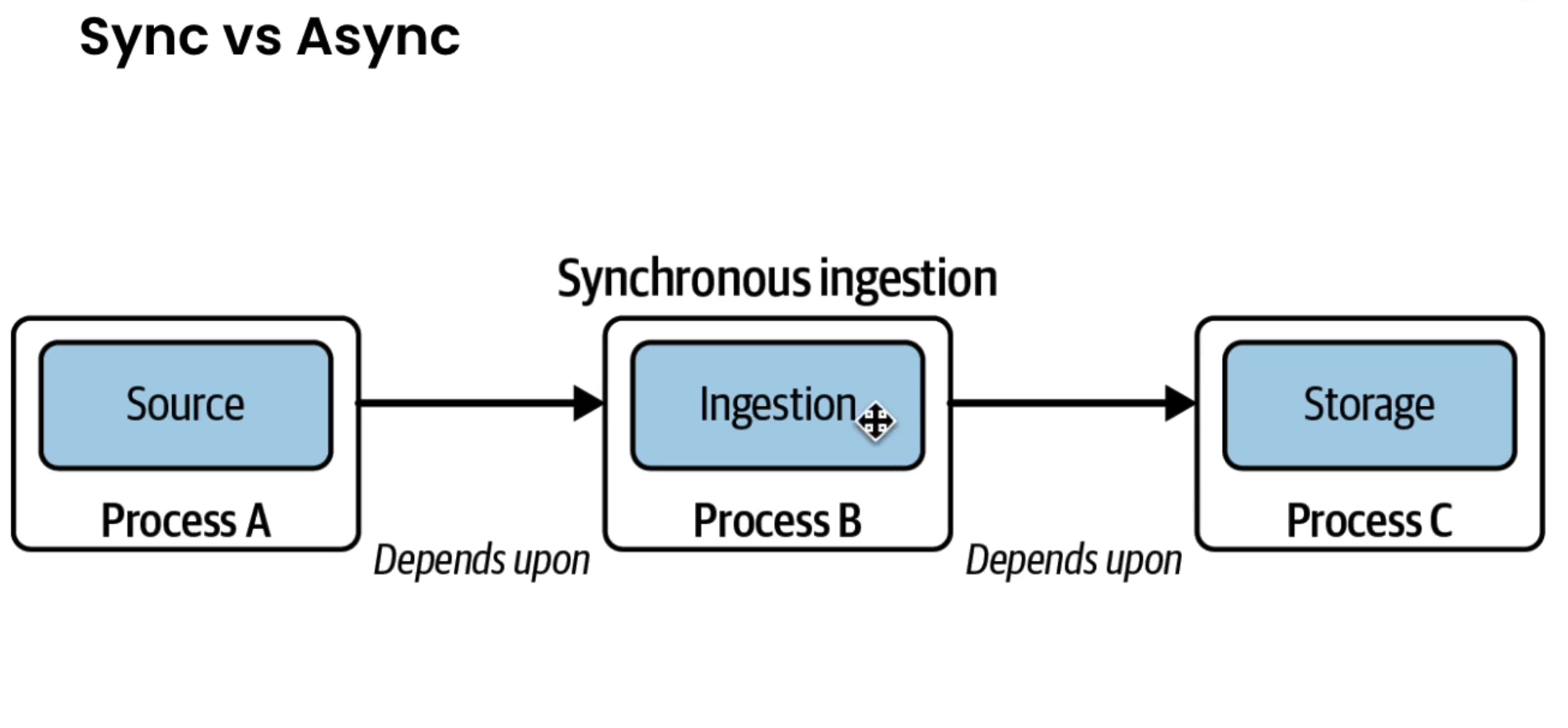
Synchronous vs Async Ingestion
- Sync. Ingestion, the source, ingestion and destination have complex dependencies and are tightly coupled.
- If one stage fails, all the other dependent ones also fail.
- Async. Ingestion is now more common and better.
- Relies on some certain conditions like some time conditions to be met and then the process starts.
- Like S3 event notifications.
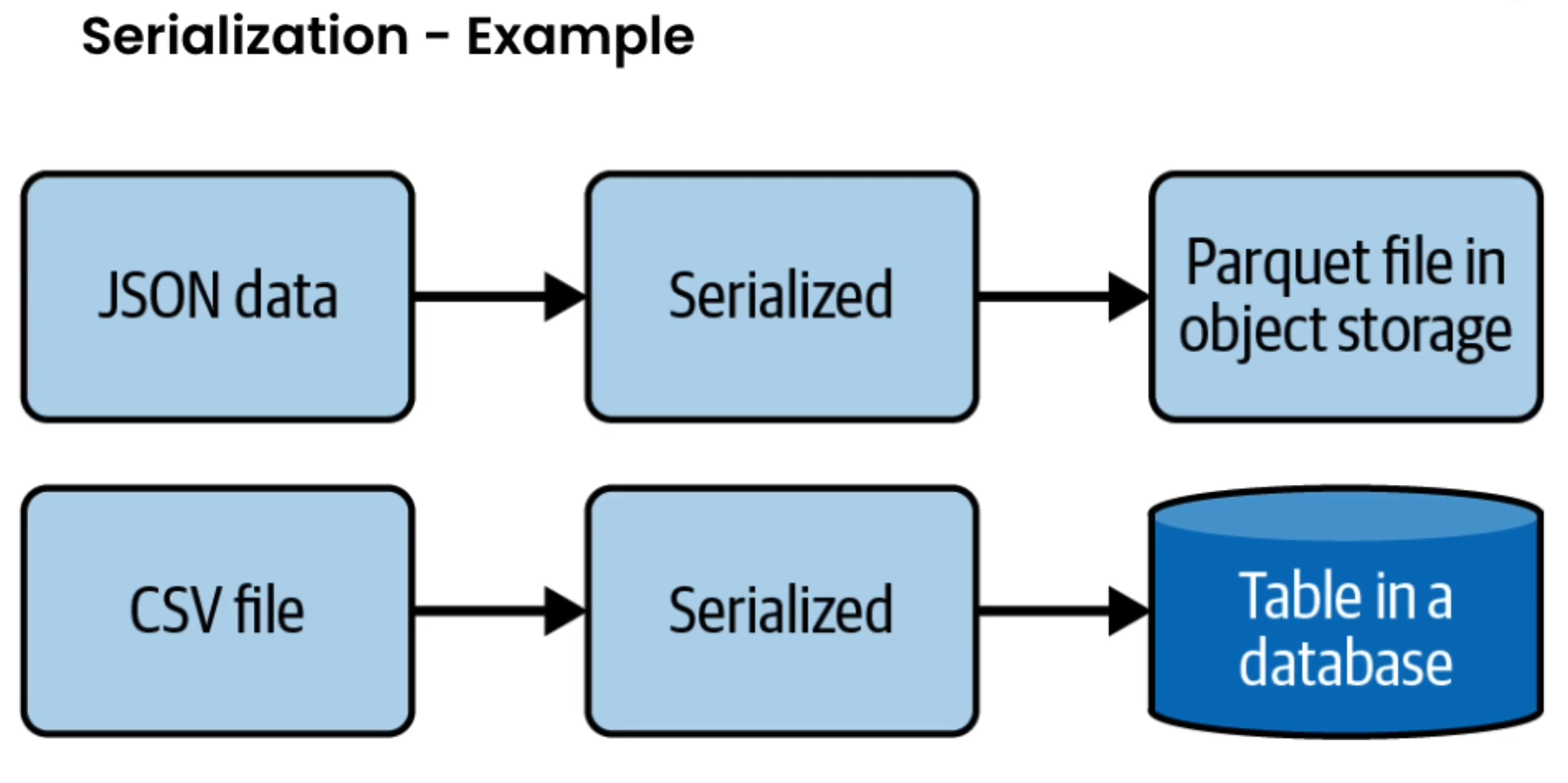
Serialization and Deserialization
- Moving data from source to destination involves Serialization and DeSerialization.
- Serialization means encoding the data from a source and preparing data structures for transmission and intermediate storage stages.
- Deserialization is the opposite.
Info
- Better to make sure of built-in buffering to account for the sudden increase in the incoming data traffic like when the db comes back online, the lapsed data will be sent in burst.
- Always look for managed service: better efficiency, cost and durability.
- Dont always reinvent the data ingestion wheel.
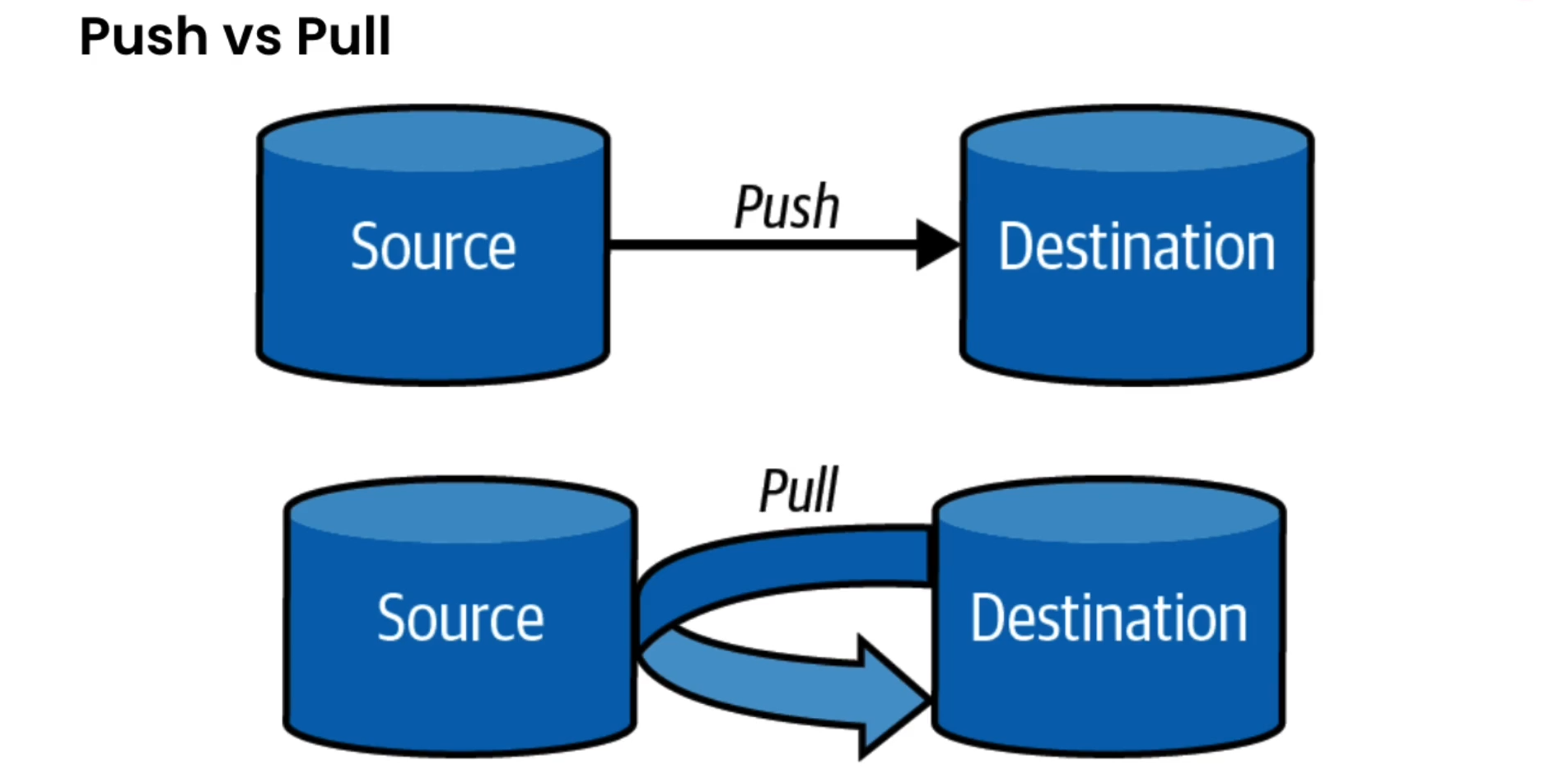
Push vs Pull vs Poll
- Push means sending data to a target.
- Pull means reading data from a source.
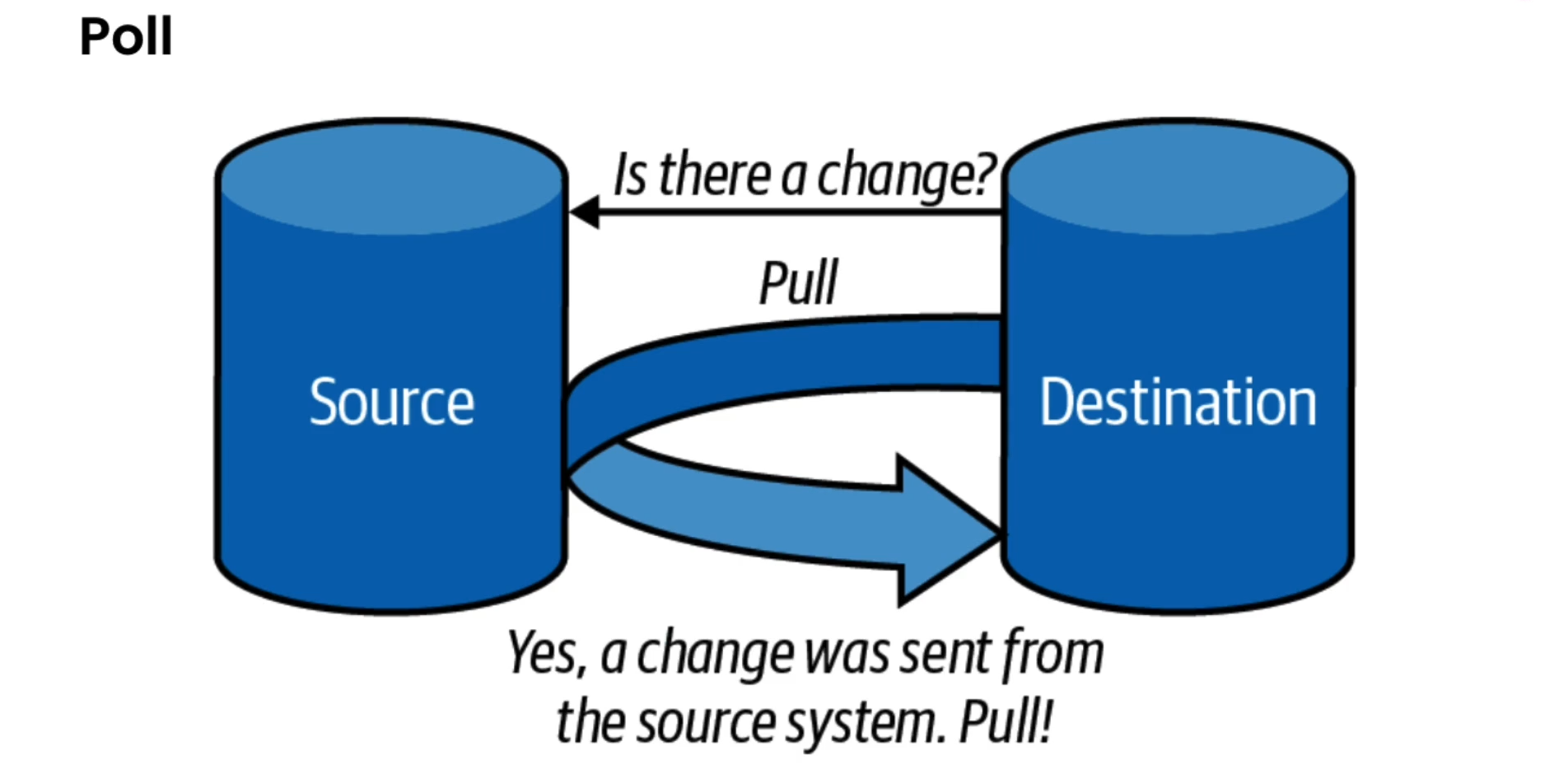
- Polling means periodically checking a data source for any changes. When changes are detected, start up any downstream task if required.
Windows
Windows are an essential feature in streaming queries and processing. Windows are small batches that are processed based on dynamic triggers.
Session Windows
A session window groups events that occur close together, and filters out periods of inactivity when no events occur. We might say that a user session is any time interval with no inactivity gap of five minutes or more.
Fixed-time Windows
-
A fixed-time (aka tumbling) window features fixed time periods that run on a fixed schedule and processes all data since the previous window is closed. For example, we might close a window every 20 seconds and process all data arriving from the previous window to give a mean and median statistic.
-
Statistics would be emitted as soon as they could be calculated after the window closed.
-
This is similar to traditional batch ETL processing, where we might run a data update job every day or every hour. The streaming system allows us to generate windows more frequently and deliver results with lower latency.
Important
As we’ll repeatedly emphasize, batch is a special case of streaming.
Sliding Windows
Events in a sliding window are bucketed into windows of fixed time length, where separate windows might overlap. For example, we could generate a new 60-second window every 30 seconds
Watermarks
A watermark is a threshold used by a window to determine whether data in a window is within the established time interval or whether it’s considered late. If data arrives that is new to the window but older than the timestamp of the watermark, it is considered to be late-arriving data.
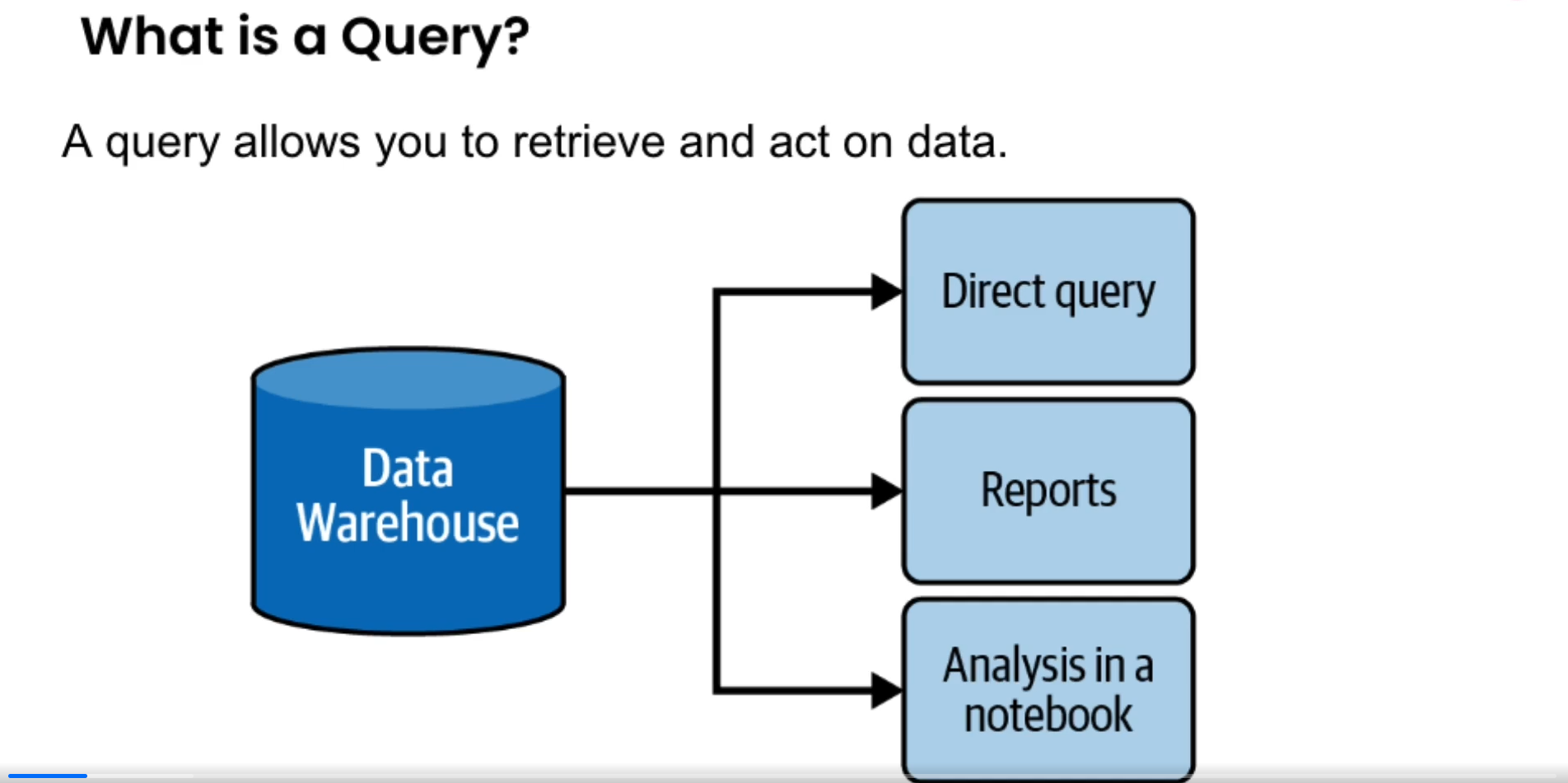
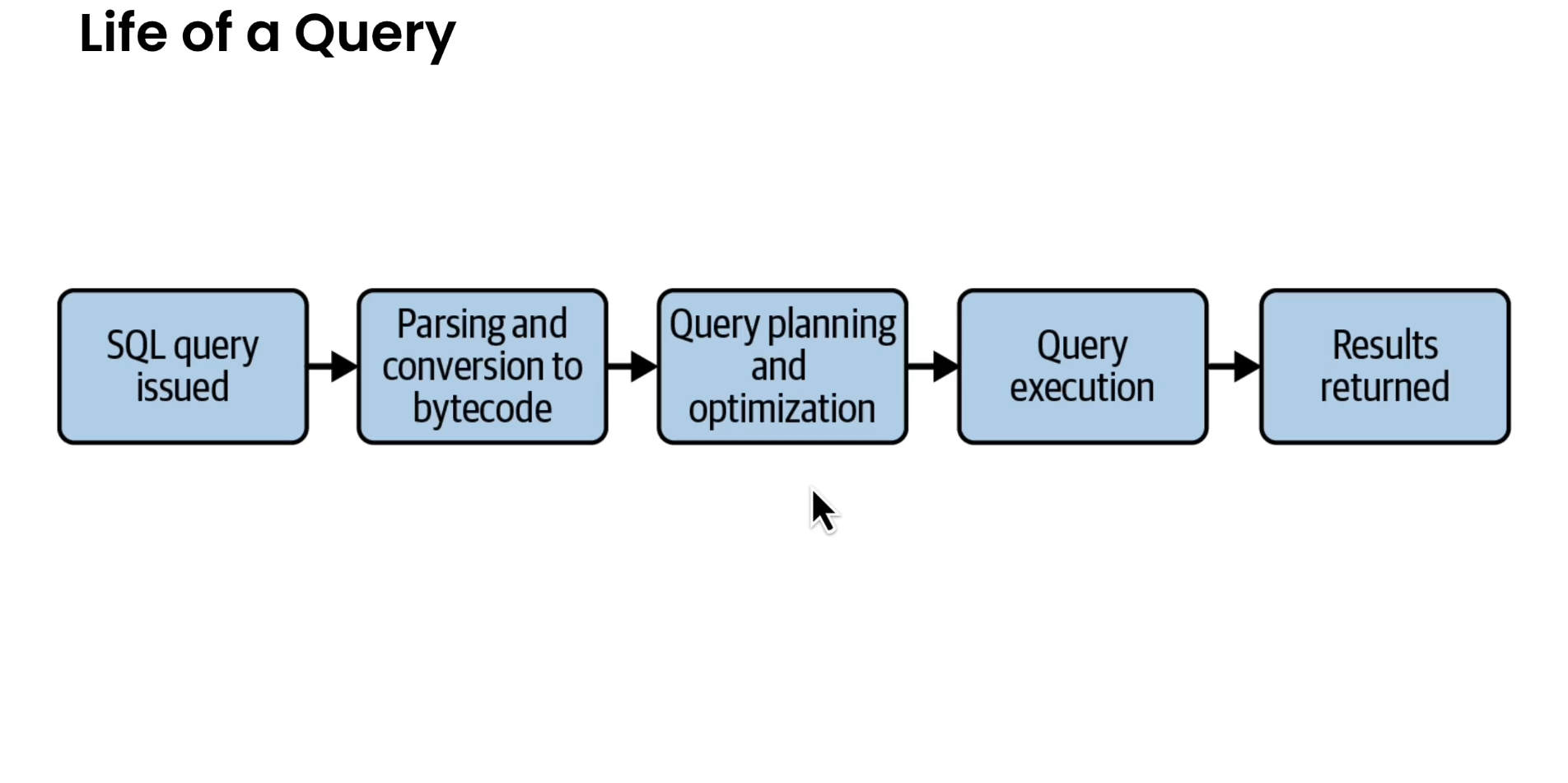
Queries
- allows us to retrieve and act on data.
DDL (Data Definition Language)
- Defines the state of the objects in our db.
- Include:
CREATEDROPUPDATE
DML (Data Manipulation Language)
- Alter/manipulate the data.
- Include:
SELECTINSERTUPDATEDELETECOPYMERGE
DCL (Data Control Language)
- Limiting the access and control to the db.
- Includes:
GRANTREVOKE
TCL (Transaction Control Language)
- commands controlling the details of transactions.
- Includes:
COMMITROLLBACK
Tip
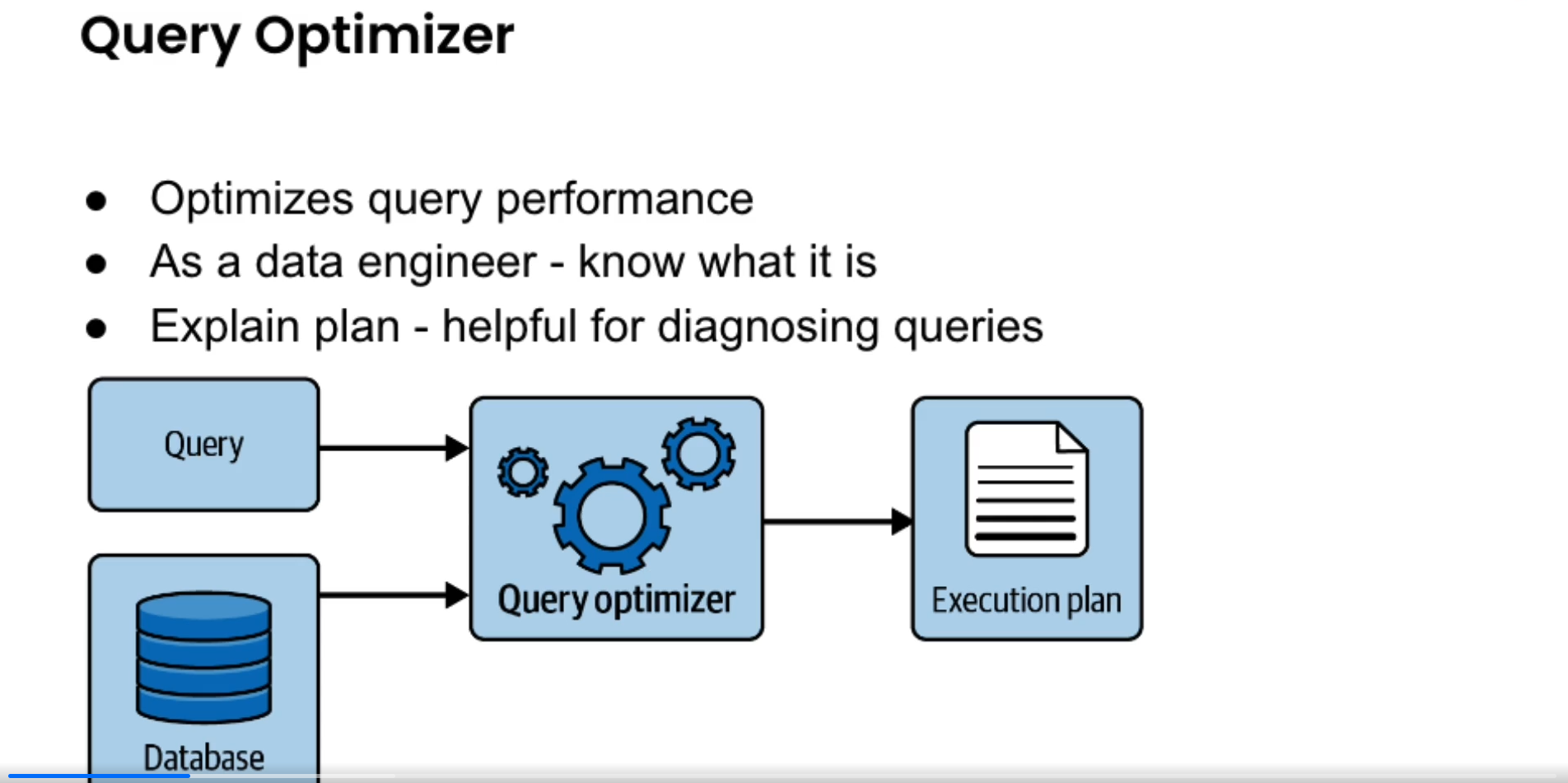
- A common technique for improving query performance is to prejoin data. If you find that analytics queries are joining the same data repeatedly, it often makes sense to join the data in advance and have queries read from the prejoined version of the data so that you’re not repeating computationally intensive work.
- Use common table expressions (CTEs) instead of nested subqueries or temporary tables. CTEs allow users to compose complex queries together in a readable fashion, helping you understand the flow of your query.
- Avoid full table scans.
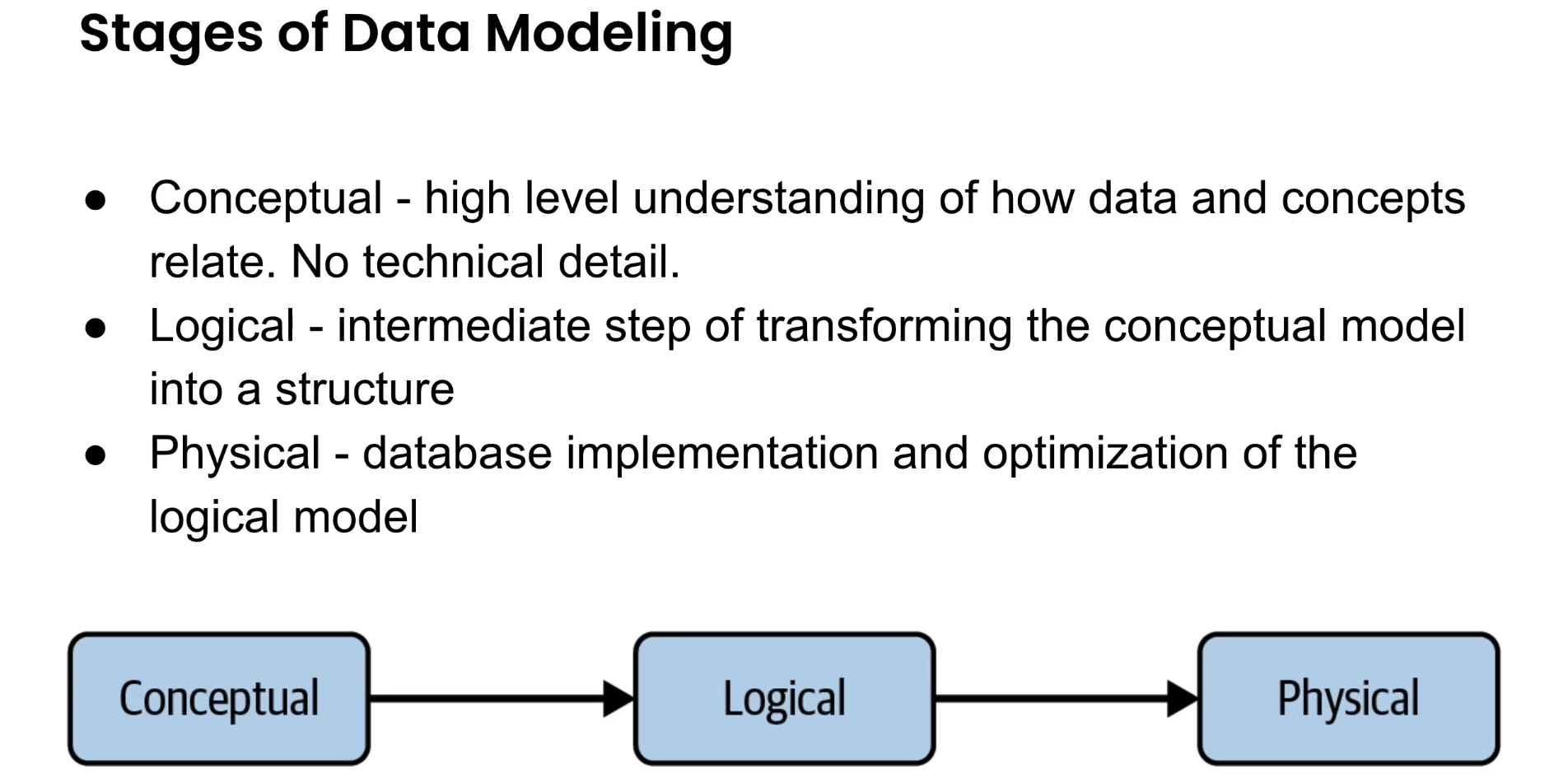
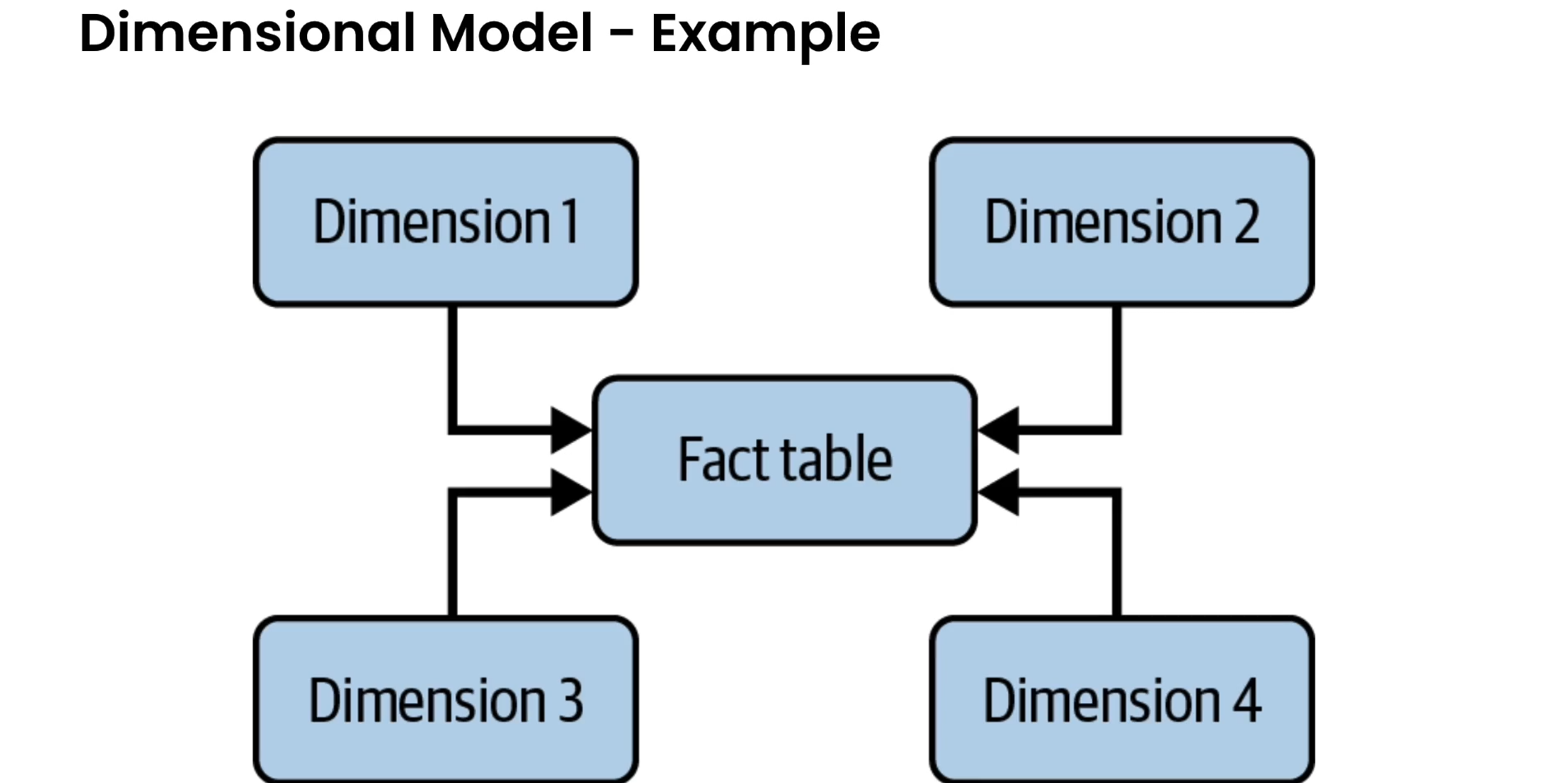
Data Modelling
Data Model
A data model represents the way data relates to the real world. It reflects how the data must be structured and standardized to best reflect your organization’s processes, definitions, workflows, and logic
Techniques
Normalization
- Normalization is a database data modeling practice that enforces strict control over the relationships of tables and columns within a database.
- The goal of normalization is to remove the redundancy of data within a database and ensure referential integrity.
- Basically, it’s don’t repeat yourself (DRY) applied to data in a database.
- Typically, applied to relational databases containing tables with rows and cols.
1NF - Each col is unique and has a single value. - The table has a unique primary key.
2NF - 1NF + - partial dependencies are removed
3NF - 2NF + - no transitive dependencies - each table contains only relevant fields related to its primary key
Transformations
MapReduce
- Introduced by Google
- Defacto processing pattern of Hadoop
- A simple MapReduce job consists of a collection of map tasks that read individual data blocks scattered across the nodes, followed by a shuffle that redistributes result data across the cluster and a reduce step that aggregates data on each node.
- For example, suppose we wanted to run the following SQL query:
- The table data is spread across nodes in data blocks; the MapReduce job generates one map task per block. Each map task essentially runs the query on a single block—i.e., it generates a count for each user ID that appears in the block. While a block might contain hundreds of megabytes, the full table could be petabytes in size. However, the map portion of the job is a nearly perfect example of embarrassing parallelism; the data scan rate across the full cluster essentially scales linearly with the number of nodes.
- We then need to aggregate (reduce) to gather results from the full cluster. We’re not gathering results to a single node; rather, we redistribute results by key so that each key ends up on one and only one node. This is the shuffle step, which is often executed using a hashing algorithm on keys. Once the map results have been shuffled, we sum the results for each key. The key/count pairs can be written to the local disk on the node where they are computed. We collect the results stored across nodes to view the full query results.
Materialized Views, Federation, and Query Virtualization
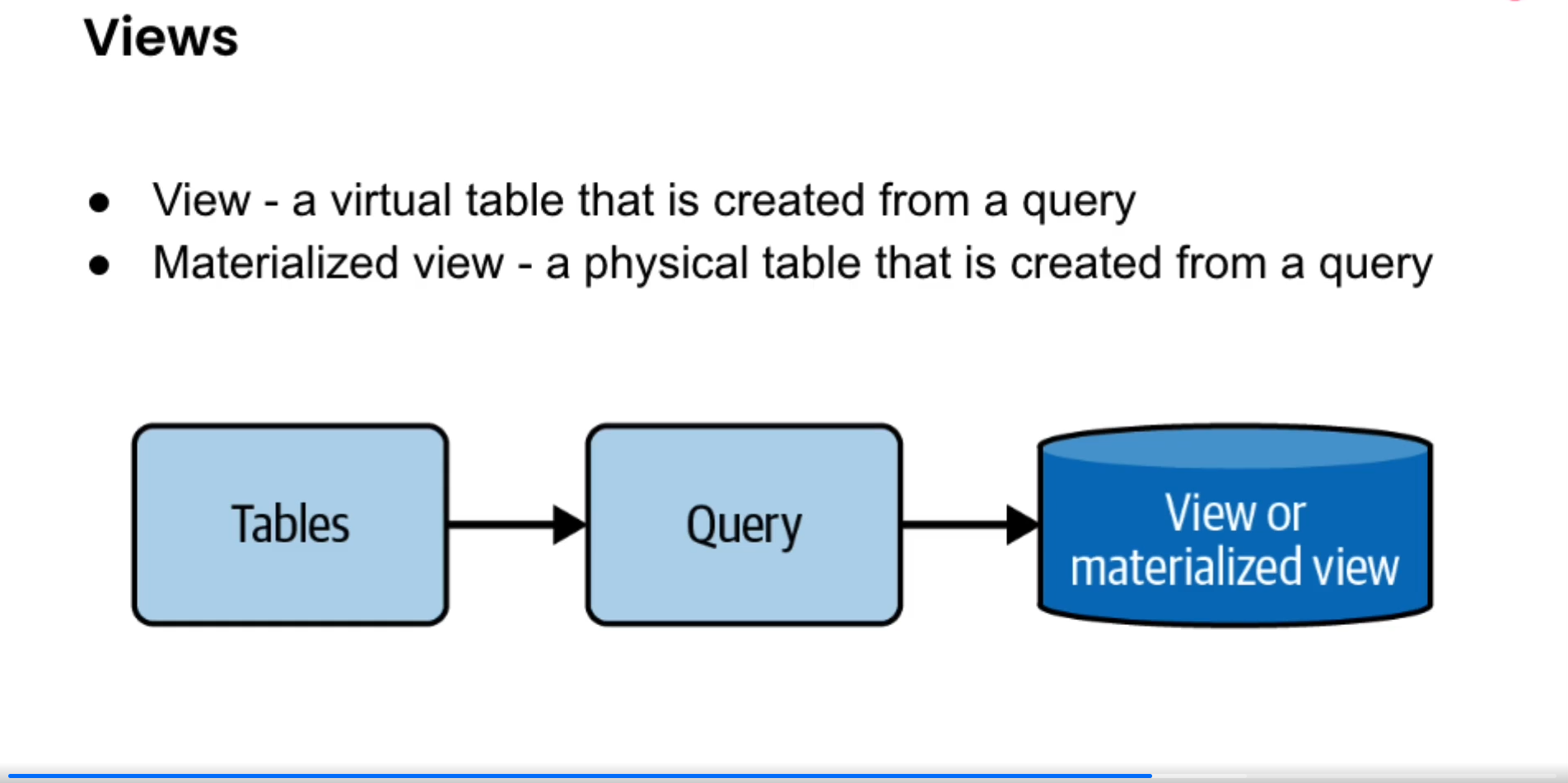
View
- A view is a database object that we can select from just like any other table. In practice, a view is just a query that references other tables.
Materialized Views
- The normal view don't do any precomputation.
- These ones, they do. So no need for computing everytime, when required.
Federated Queries
- Federated queries are a database feature that allows an OLAP database to select from an external data source, such as object storage or RDBMS.
- For example, let’s say you need to combine data across object storage and various tables in MySQL and PostgreSQL databases. Your data warehouse can issue a federated query to these sources and return the combined results
Data Virtualization
- Data virtualization is closely related to federated queries, but this typically entails a data processing and query system that doesn’t store data internally.
- Eg. Presto, Trino
- Data virtualization is a good solution for organizations with data stored across various data sources.
Security & Privacy
- Just keep these in mind:
- Negative thinking is good sometimes: allows us to think about various scenarios
- Always be paranoid
- Principle of least privelege
- Always back up the data
- Protect the creds using good methods
- Encryption
- Have logging, monitoring and alerting enabled
Serialization formats
Row-based serialization
- organizes data by row
- They are:
CSV
- good and most-common
- but avoid using csv files in pipelines as they are highly error-prone and deliver poor performance
XML
- legacy
JSON and JSONL
- popular for data storage
- JSONL is a specialized version of JSON for storing bulk semi-strucutred data in files
- stores sequence of JSON objects, with objects delimited by line breaks
Tip
JSONL is an extremely useful format for storing data right after it is ingested from API or application.
Avro
- row-oriented data format designed for RPCs and data serialization
- encodes into binary data with schema specified in JSON
- popular in Hadoop systems
But columnar formats offer significantly better performance.
Columnar Serialization
- With columnar serialization, data organization is essentially pivoted by storing each column into its own set of files
- Storing data as columns also puts similar values next to each other, allowing us to encode columnar data efficiently.
Parquet
- columnar format
- excellent performance (R/W) in data lake environment
ORC
- Optimized Row Columnar is another one.
- Popular with Apache Hive